
Where the dummy is me!
It took me so long to make myself a decently clear idea about this topic that I eventually took a breath and put it down in form of a single (hopefully) organised story. Enjoy!
Table of contents
The problem we have, and how does it matter
DACs’ business is receiving digital files and re-convert them into analog electrical signals. Such signals are then amplified and sent to drivers (big loudspeakers or small IEMs, it doesn’t matter now) to become audible music.
Sadly while doing its job a DAC, any DAC, fatally produces “spurious copies” of each note. .
Such unwanted “note replicas” are higher frequency copies of their relavant intended note, and such “higher” frequencies are beyond the humanly audible range. That’s why we call such artefact notes “Ultrasonic images“.
For better precision these unwanted images can happen only starting from one half of the input digital signal’s sampling frequency.
So for example on an ordinary CD-quality track, thus sampled at 44.1KHz, our Images will only happen above 22.05KHz. Which is why they won’t be audible: the human auditory system is only receptive to sounds up to 20KHz (and only when it fully works…).
If they are not audible why the heck do we care about them? For two reasons.
First reason: the frequencies at which these notes are generated are not audible by our ears, but are significant for our physical drivers (the tweeters in our speakers) – which overheat and overwear and can even break if they receive them or they receive them “too loud”. Indeed, on a wider horizon, the DAC might also produce or anyhow transmit various other forms on unwanted high or very high frequency “notes”.
For this reason alone we should find a way to avoid or kill such images, like any other ultra high frequency stuff.
The second reason is a bit more complicated.
On certain conditions when two notes close to one another are played, a sort of “reciprocal disturbance” happens between such two notes. That’s called “Inter-Modulation Distortion” (IMD).
Let’s get this picture as a conceptual example:
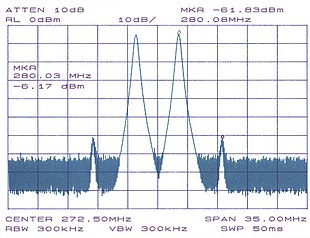
Suppose our “real” notes are the two big peaks in the center. Sometimes, they will “autogenerate” those shorter and leaner ones you see at their sides, one on the left (lower frequency), one on the right (higher frequency). The picture shows a case with only 2 spurious notes generated, but they could be more.
Now let’s suppose that the left real note in our example actually is one of those unwanted Ultrasonic Images produced by our DAC. As we said above, it will be on a too high frequency to be heard. Let’s suppose it’s at 21Khz. So of course it won’t be audible but big chances are that it’s “left side baby copy” might well be “distant enough” from “mummy” as to fall below 20KHz, so within the hearable frequency range.
That’s why this is called “fold-back effect”, and that’s the second important reason why we need to help our DAC getting rid of high frequency images generated during the reconstruction process in the first place.
Summary: DACs produce spurious ultrasonic images. Those need to be taken care of to prevent damage to drivers, and audible sound alterations.
The solution, and its drawbacks
How do we get rid of the ultrasonic images? With a filter.
That is, with some circuitry that (simplistically put) makes sure that once the DAC has done its job reconstructing our wanted music + those extra unwanted notes at higher-then-audible frequencies, a cut down is imposed on all frequencies above the maximum humanly audible level – effectively “filtering” them off.
No ultrasonic images, of course, so also no “fold-back” IMD-generated audible spurious notes.
Was it so easy? Well no, not so easy.
This filter we need is an electrical circuit and as such not “perfectly ideal” as we would dream it to be. If by my description above you imagined a sort of guillotine blade cutting the crap out, with no side effects, well… no.
What we would ideally want it a filter that leaves audible music totally unoutched, and kills all and only those ultrasonic images. Instead, real world filters will either let some of those ultrasonic images pass through, or apply some change to audible music, or both.
Depending on how it’s realised, the filter will have inaccuracies and side effects that we can’t entirely avoid. Such imperfections can first of all be more or less important depending on the original music’s sampling rate, and besides that the unwanted audible sonic changes might be more or less unwelcome by each particular user.
So that’s why it’s in a sense nice if a DAC device offers a choice amongst different filters: we will end up choosing the best – or least bad, if you wish – one depending on our tastes.
So let me explain about these filters imperfections and how they impact on our music. Let’s start with the inaccuracies.
Fast and slow filters
To describe how these filters work we use certain methods and graphical representations. Here is one.
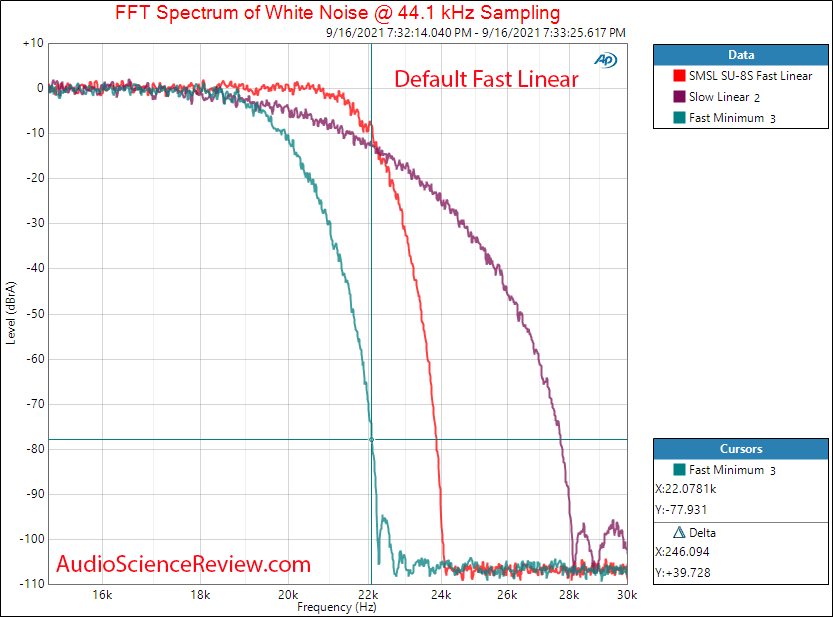
This graph shows the behaviour of 3 different filters as they are implemented on a certain DAC. Forget about the specific DAC model now, this is just to describe in principle how these filters work and inhowmuch can they be different from one another.
This graph plots the attenuation (the reduction of “loudness”) that each filter imposes to the analog signal (our music) that’s coming out of the DAC.
On the X axis we have the frequencies. Remember human audible music gets as high as 20Khz.
On the Y axis we have the output “power” reduction which that filter applies, expressed in dB. Zero dB = zero impact. -110dB = shut up!
The signal being processed (the “music”) in this specific case is white noise, so a sort of “artificial music” composed of notes of all frequencies, all at the same power level. The white noise sampling rate in this example is 44.1Khz.
If there weren’t any filter, the graph would be an horizontal line accross the entire graph space, stuck on 0dB.
Let’s look at the graph lines, starting by following them from their upper left point, where they hit against the Y axis, and going towards the right.
All lines are equally flat up there, one on top of the other, and they all indicate zero dB attenuation (marked on the Y axis). That means: all those filters apply no attenuation at all on all frequencies until… (follow the plots going right by at the same time reading down on the X axis) …at least until 18KHz.
If we now keep “going right” from 18KHz, we see the various plot lines spreading apart.
The green and the purple lines are the first which start to “go down” right after 18Khz. The red line stays instead flat horizontal, stuck on 0dB attenuation, until above 21KHz.
The green line “drops” faster than the purple one. At 20KHz the green line is already at approx -12dB, while the purple line is still around -5dB. The green line “drops dead” (-110dB attenuation or so) just above 22Khz. The purple line reaches the same “full attenuation” level not before 28KHz.
So what does this mean?
We know that ultrasonic images can only happen above 50% of the input sampling frequency, in this case 22.05KHz.
The graphs tell us that the “green filter” (i.e. the filter represented by the green line) gives full attenuation to all signals lower than just above 22KHz so our green guy will kill all our ultrasonic images, we won’t get any.
Viceversa the purple filter will take its sweeter time before dropping down, and will let quite some ultrasonic images pass through. All those until approx 28KHz will pass, although progressively more and more attenuated as their frequency goes up.
Both the green and the purple filter also have a visibile drawback: they both start their job from 18KHz, which is still within the audible range.
While “dropping faster” to be able to cut everything above 22Khz, the green filter applies a stronger cut on the higher part of the audible range (-12dB or so at 20KHz, which is a lot). The purple filter is more permissive with images, but also less punitive on trebles (only -5dB or so at 20Khz).
Let’s look at the red line now.
Its vertical part is visually roughly parallel to the green one, it’s just offset towards the right by 2KHz.
So how does the red filter work? Test if you got the drill from above.
The red filter stays at 0dB attenuation until 21Khz+ so it won’t touch any audible sounds. Then, it will drop quite rapidly, and will reach down dead at approx 24Khz. So, it will let “some” ultrasonic images pass through (only those from 22.05 to approx 24Khz)
Summarising: all these filters have some sort of inaccuracy. These of graphs tell us that which sound frequencies are cut down by our filters, and how much power do our filters take off from them (zero, full, or something in between).
One filter makes fewer frequencies pass, the other lets more of them through. And this, already, prompts us to wonder which option is best for us.
But before that, let’s investigate about filters’ side effects.
Ringing, everywhere
Let’s talk about the frequencies (the musical notes) which our filter lets through.
Shall those notes pass through really unmodified ? Or will the filter introduce any audible modification to them?
To study how these filters behave in terms of transparency we use a different test procedure, and graph. While before we submitted “all frequencies at once” (white noise) to the filter, now we’ll oppositely submit just one note to the filter – an as “neat”, quick, sharp and clean note as possible. And we’ll plot what our device (the filter) outputs as a result.
We call such single clean input note “impulse”. And the output is an “impulse response”.
We can imagine to create a pure impulse as a digital file where all samples are set at zero value (representing pitch black silence of course), and just one sample has the digital value of a single, loud note.
Assuming that note plays at a frequency which the filter is not attenuating, an ideal filter will of course reconstruct precisely that note in analogue form, and nothing else. Will a real world filter behave differently?
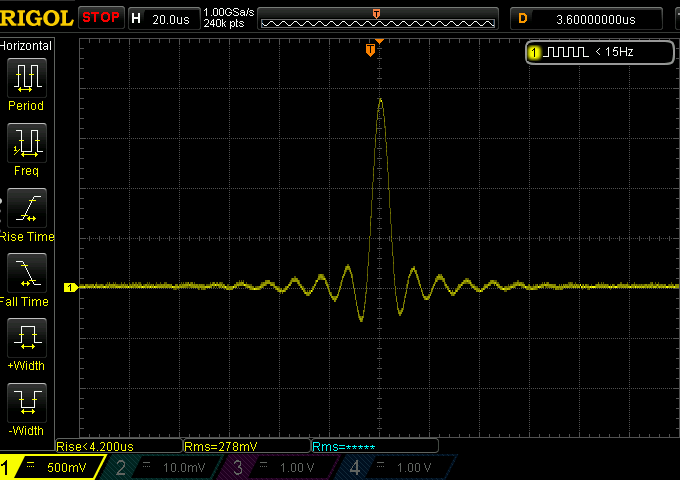
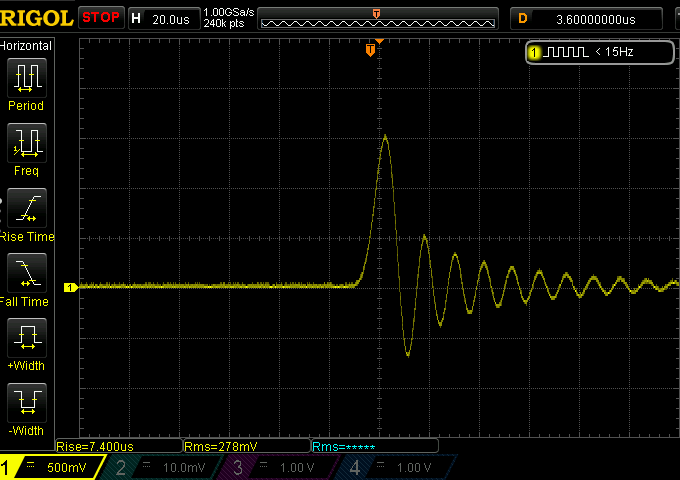
This is a good first example of impulse response graph.
(For the illustrations I am helping myself with the pictures published within this article, which is very well written by the way, and might also be interesting for you to take a look at).
On the X axis there’s time. On the Y (vertical) axis there is Voltage, so ultimately output power.
The plot of an ideal filter applied to the DAC’s reconstruction of an ideal impulse would be a dead flat horizontal line at 0 Volts (total silence), until a precise time where voltage pops up for a very brief moment (the Impulse), and then comes immediately back down to zero, to continue dead flat onto zero forever thereafter.
The picture above is instead the plot of a real world situation.
The peak in the middle is what we expected: the impulse note reconstructed based on the single <>0 digital sample in the input file. So far so good.
The unexpected part is those ripples to the left (so, in time, before the note) and to the right (so right after the note).
If the note we are talking about is audible, those ripples will be audible in terms of (faint) “fringes” to the notes. That note will not come across perfectly neat as it should. Ideally we would not want those ripples then, but let’s not commit suicide yet. The ripples before the note are called “pre-ringing” by the way, those after are called “post-ringing”.
The graph above reports the impulse response of a fast filter.
If you remember, a fast filter is what in general seems most desireable as it cuts ultrasonic images quickly. Now we find a quite important drawback though: a fast filter adds unwanted note alterations both before and after each note.
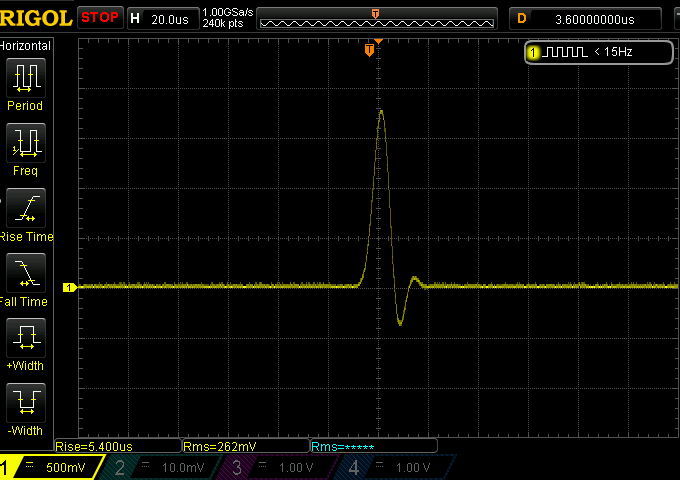
Let’s see how a slow filter behaves:
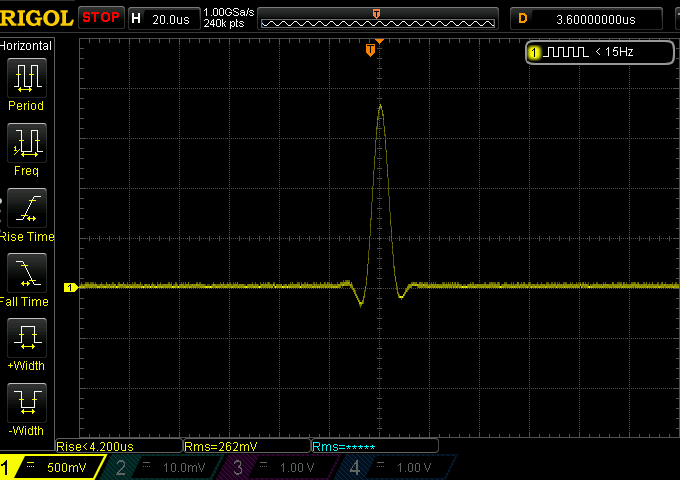
The central part is very similar of course, but the ripples (the “ringing”) are minimal in comparison to the fast filter case.
So we know from the previous chapter that the slow filter is less effective in terms of ultrasonic images cutting, but it turns out to be much less impactful in terms of changes on the musical notes themselves.
Ringing, single-sidedly
The fast and slow filters we saw in the previous chapter produce more or less ringing both before and after their impulse response, are sometimes called “linear phase” filters.
In tech talk, the “phase” of filter refers to a delay. Too complicated. Here, let’s concentrate on the effects more than on the technical causes.
On linear phase filters the impulse energy is in its maximum part concentrated at the exact time when the note needs to be played, with some fringes of energy “escaping” some time before and some time after the pulse. The two filters we saw before obey to this decription: the high peak is in the center of their graph, and the ripples are at both its sides.
Other filters can be created which instead concentrate the maximum part of the incoming energy at the beginning of the impulse response, and overflow only onto the time past that. Like this:
A filter like this is called a “minimum phase” filter.
The impulsive part (the main note) is totally similar to the fast, linear phase sibling. The ripples, however, are only after the note.
Open brackets. As you’ll notice this graph has “a lot” of ripples – although only on the right side – so this will be a “fast, minimum phase” filter. Close brackets.
The amplitude of the ripples after the note is bigger (ripples are taller) compared to that of the ripples before or after the note observed in the “fast, linear” case. Indeed, it’s double. The fact is that the total energy is the same: in the linear case it gets distributed “a bit before and a bit after” the “main event”, here instead the ex-flow it’s all “delayed to after” the peak note.
Soooo……. there is no pre-ringing!
Lastly, let’s consider a “slow, minimum phase” filter. How will it be?
As expected: similarly to the “slow, linear phase” case the ripples are minimal compared to the fast alternative, and similarly to the “slow, minimum phase” case the ripples are only after the impulse. No pre-ringing.
There are quite a few other ways to build reconstruction filters but it was never my intention to write an encyclopedia. These 4 cases are quite enough for us to get where the main trick stays.
Ringing ?
I mentioned before that we would ideally want ringing not to be there at all. Do we really ? Less than it seems, actually. That, for two reasons.
First reason.
It’s crucial to note that our internal auditory organs… do ring too.
When our internal ear receives an “impulse” (a relatively strong, sudden sound) our organs will vibrate in conjunction with that note… and for a short time after it. This is so physiological that our brain… knows!
Our perception of a “neat” (not reverberating, not “persisting”) sound is the result of an originally neat note hitting our ears. There, some human post-ringing is added, then it all goes to the brain which… subtracts (tares off, if you wish) the ringing and tells us that the note was “neat”.
On the flip side, our ear organs do not pre-ring when they receive a sound. So when our brain gets some “thing” coming before a sound it will “remark it immediately” as “odd”.
Given this, a filter-inducted note post-ringing will actually be much less important that it seems on paper. As long as it is modest in amplitude and/or length it will be masked in full or in part by our physiological system.
The filter’s pre-ringing instead, that will most matter. As our brain does not know what pre-ringing even means (!) a note affected by even modest pre-ringing will first of all be decoded as “strange”, “not totally right”.
Second reason.
Ringing will not happen on each single note played by the DAC. Oppositely, it will happen only on somewhat “unlegit” notes: e.g. those connected with clipping, or with pre-existant ringing.
As it looks, then, we should never actually have ringing as long as we listen to good quality digital tracks. Do we?
Yes, precisely. Too bad that “good quality digital tracks” are surprisingly rare. Ever heard of Loudness War for example? Good audiophile-quality masters are, indeed, extremely rare to find. The last place where to look for some in my experience is an online streaming service (any online streaming service). But that’s another story.
Connecting some dots
Let’s summarise what we learnt until now:
- Bloody DACs create unwanted artefact notes
- Such artefacts only appear at frequencies higher than 50% of the original digital file sampling rate (so e.g. for a 44.1KHz file they start happening above 22.05KHz)
- Those artefacts need to be removed as they create problems both audible (affecting the music) and non audible (affecting audio devices)
- To remove them we use filters, which are engineered in different possible ways
- Filters of different types have different scope/efficiency spans, and come with different side-effects.
About filters we learnt that:
- Fast filters start killing notes very few KHz higher in frequency from the filter’s inception frequency.
- Slow filters oppositely let notes of much higher frequencies vs their inception frequency pass through.
- Linear filters (be they fast or slow) add some note imperfection called ringing both before and after the notes
- Minimum phase filters (be they fast or slow) add stronger ringing after the notes, but none before them.
Finally, we noted that the human auditory system has some modest physiological post-ringing, but no pre-ringing.
So in summary: filters do kill unwanted ultrasonic frequencies but they introduce some issues while doing that, so there’s a tradeoff to be found between how strict is the filter and how much of we can afford bear, or even we appreciate, filter’s drawbacks.
To make an example of such tradeoff let’s go back to the graph we originally used to learn how these filters macroscopically work. Here it is, do you remember it?
The specific case is an ordinary CD-quality 44.1KHz digital track.
Which will be the pros and cons of those 3 filters ? Try yourself !
The Green filter
Down below, its plot reaches full attenuation status at 22.05KHz. So it guarantees us that not one of the bloody ultrasonic artifacts will escape. No ultrasonic artefacts, no audible fold-back frequencies. Perfect.
Up above, its plot stars flexing off from 0dB (no attenuation) down at approx 18KHz. Let’s remember audible frequencies top at 20Khz. So it will indeed “cut” some of the top treble sounds from our track (and something else too – more on this below). This filter will take a little bit of “air” off sound, and also limitate soundstage size drawing. So-so.
A filter letting a window of just 22 – 18 = 4KHz open is indeed a fast filter. So it will be one of those filters producing significant ringing. Nevertheless (look at the Data box on the picture’s top right) it’s a minimum phase filter, so its ringing will exclusively be extended after the notes, so mostly covered by our physiological one. Good.
The Red filter
Full attenuation at 24KHz. So this filter lets a small window of 24 – 22 = 2Khz “open” for Ultrasonic images to pass through. Ultrasonic images are not welcome anyhow, but at least they will not be audible in this case. Some will generate audible fold-back notes though. So-so.
Inception higher then Green, at approx 21Khz. So it will not harm audible trebles (<=20KHz) , won’t take “air” off the sound; it will just still harm soundstage a bit (more on this later). So-so, but better than the Green.
It’s even faster than the Green (takes only 3KHz to go from 0dB to full nuke), so its ringing will be a tad more than the Green’s. Most importantly (see the box up right) it’s a Linear filter. So it will have both post- and pre-ringing, and the latter will be perceivable in terms of softer notes attack and in general lesser note sharpness. So-so (but it also depends on tastes).
The Purple filter
Full attenuation up at 28KHz. So quite a lot artefacts will pass through (all those having frequencies from 22Khz to 28KHz), and there will be a more significant generation of fold-back audible images. Meh.
Inception at 18Khz, like the Green. But it is definitely a slow filter. So it will harm trebles and soundstage like the Green one does, but with a much, much softer hand at that. At 20KHz the Green filter attenuates already approx 12dB, which is a lot, while the Purple only drops approx 5dB at 20Khz. Not ideal, but close to.
Finally, it’s a Linear filter. So it will have post- and pre-ringing. But unlike the Green, being a slow filter its ripples will be small so the pre-ringing will be very modest. So-so (depending on tastes), but better than Red.
[Size] Sampling frequency matters
It’s not entirely accurate to take 20KHz as the top frequency that matters to our purpose of an optimal music reproduction.
While it is in facts true that no human hear can perceive sounds higher than 20Khz frequency (and only being young, too!), it is also true that music is not made of sounds only, but also of timing.
Information about silences (their length), echoes (their timings) etc, can involve frequencies much beyond 20Khz. Sileces, echoes etc are what adds spatial accents to the sound.
Of course not all digital tracks will be sophisticated enough to even contain such high(er) frequency space-related information in the first place. A bad recording is a bad recording, and do we want to talk about bad mastering? Sheesh.
Also, it does take a not too ordinary DAC to appropriately make use of such >20KHz (see my article about Apogee Groove for an example, and some hint on the reasons for this).
When talking in general terms as we are doing today, however, we must appreciate that frequencies above 20Khz are not easily expendable as one may think at first.
Which of course makes our filters story even more dramatic. If you read back the conclusions of the previous chapter – those commenting on the pros and cons of the Green / Red / Purple filters we used for training – this is the reason why I underlined that all three filters would harm soundstage a bit.
Now on to some good news, for a change.
Suppose we have our digital tracks sampled at sample rate much higher than ordinary CD-quality. Let’s say they are at 96Khz.
The DAC will start producing its ultrasonic artifacts starting from (remember?) one half of that, so in this case artifacts will not have frequencies lower than 96/2 = 48Khz.
That’s a lot above our human hearing upper limit, and also up quite enough to let most if not all those high(er) frequency samples partaking to spatial cues that we mentioned just before.
Connecting more dots
If we can count on digital tracks sampled at rates much higher than 44.1KHz, then the situation changes when it comes to the pros and cons of fast and slow filters.
Let’s recycle our training case: the green / red / purple filters. Let’s assume the track is sampled at 96Khz instead of 44.1KHz this time. Artefacts will start to appear from 48KHz on up.
The Green filter would in this case drop dead at 48KHz, killing all artefacts. Perfect like before. It would start from 4Khz lower, so from 44KHz. Unlike the previous case, this would not harm treble air, nor likely spatial-related frequencies at all. Perfect (thanks to the higher incoming sampling rate!). As a fast, minimum phase filter there would be some just modest post ringing. Good!
The Red filter would drop dead at 50KHz so it would let 2KHz open for Ultrasonic images. Not totally welcome yet surely unaudible. Fold-back images would be there, but too far off from audibility threshold for some to pass it. Nice-ish. Inception would be at 45KHz so still zero harm to treble tones nor to treble air, and hardly any chance of chopping on soundstange. Good. Still a fast linear filter so its pre-ringing smoothing notes down would be there. So-so (tastes dependent).
The Purple filter would drop dead at 54KHz so even more (unaudible but potentially harmful) ultrasonic artefacts and little to none of their IMDs would reach down enough to fold-back into audibility. Not so good. Inception at 44KHz so again zero harm to treble notes, treble air and likely to soundstage too. Good. It’s a linear filter so smoothing notes down due to pre-ringing. So-so (tastes dependent).
Choices
So in the end which reconstruction filter would I choose – if given the option of course ?
Like in many other aspects of audio (and of life)… it depends.
First and foremost, it depends on the the digital music’s sample rate. Sarting from higher up, fold-back images generated by the slow filter will hardly if ever fall into audible range. Which makes a slow filter’s main benefit – its significantly more modest ringing – a much more “affordable” option of course.
This is so much true that whenever at all possible and doable at a decent technical level, up sampling lower rate (44.1/48KHz) tracks onto at least twice the rate is a no brainer to me!
Another discriminating element to consider is one’s preference in terms of note transients. I do tend to prefer short transients, cleaner timbres. Therefore I sharply lean towards minimum phase filters, which unlike linear filters are immune from pre-ringing.
When my tracks are desperately 44.1KHz, and my transport does not give me a [viable] up sampling option, then I’m kinda forced to opt for a fast filter of course. Which will generate much stronger ringing compared to the slow alternative, and will make minimum phase even more desireable vs linear!
Lastly, all of the above is to be taken “in principle”, and not necessarily “in practice”, as the path going from principles to practice passes through actuality, in our case it pass through the particular DAC devices we actually have available. Our DAC may not offer a choice of different filters. Or, may offer only a very restricted choice. Or even may offer various filters of which some well implemented and others badly implemented.
Very long story short: the above is how it should work. How it does work can only be told by our ears – with good peace of all die-hard objectivists.